Bug/disk order bug during ingest #4548
Conversation
| throw new ServerApiException(ApiErrorCode.INTERNAL_ERROR, String.format("No attached disks found for the unmanaged VM: %s", instanceName)); | ||
| } | ||
| final UnmanagedInstanceTO.Disk rootDisk = unmanagedInstance.getDisks().get(0); | ||
| UnmanagedInstanceTO.Disk rootDisk = unmanagedInstance.getDisks().get(0); |
There was a problem hiding this comment.
@DK101010 Since disks list for UnmanagedInstance is created by CloudStack only, will it be better to always prepare that list in a way that first disk is always ROOT disk.
Relevant code can be found in VmwareResource class.
There was a problem hiding this comment.
@shwstppr ahh ok, yes of course this is a better solution, i will check this.
 GabrielBrascher
left a comment
GabrielBrascher
left a comment
There was a problem hiding this comment.
@DK101010 thanks for investing some time in contributing to the project. I see that it is your first Pull Request, so ... be welcome :-)
I see that the code still will be updated to address @shwstppr; therefore, my review here may not fit after these changes.
I would like to bring some points that can be improved, with these points I would also raise some attention to the lack of Pull Request description. A PR description is a key piece of each contribution, being used as future reference if/when necessary. Can you please enhance the PR description?
server/src/main/java/org/apache/cloudstack/vm/UnmanagedVMsManagerImpl.java
Outdated
Show resolved
Hide resolved
server/src/test/java/org/apache/cloudstack/vm/UnmanagedVMsManagerImplTest.java
Outdated
Show resolved
Hide resolved
@GabrielBrascher thanks for your welcome :). |
1cf953f to
e3c8143
Compare
|
@blueorangutan package |
|
@rhtyd a Jenkins job has been kicked to build packages. I'll keep you posted as I make progress. |
|
Packaging result: ✔centos7 ✔centos8 ✔debian. JID-2498 |
|
@blueorangutan test |
|
@rhtyd a Trillian-Jenkins test job (centos7 mgmt + kvm-centos7) has been kicked to run smoke tests |
| String num = disk.getLabel().replaceAll("\\D", ""); | ||
| // return 0 if no digits found | ||
| return num.isEmpty() ? 0 : Integer.parseInt(num); | ||
| return disk.getPosition() + (disk.getControllerUnit() * 100); |
There was a problem hiding this comment.
@DK101010 In the code above this section we set ControllerUnit only for VirtualIDEController and VirtualSCSIController device type otherwise it remains null. Should we add a null check here?
There was a problem hiding this comment.
@shwstppr Good point, But how realistic is it to say that we have a volume with a position and without a controller id.? I talked with my administration and network colleagues and other controller types like NVME and SATA have also a controller id.
Therefore I think about it to add an exception in the else condition? What do you think?
There was a problem hiding this comment.
@rhtyd damn, your are right, that was to quick from my side, the catch block catch all exceptions :(.
Hmm ... is it ok to remove the catch block ?
In my opinion the ingest process should be canceled if not all volumes ingestible. What do you think @rhtyd @shwstppr ?
There was a problem hiding this comment.
Yes, as long as that's acceptable
There was a problem hiding this comment.
I think IDE and generic SCSI (VirtualSCSIController) will cover all disk controllers. If we are getting any other type of VirtualController as a disk, an exception seems correct to me. However, the error message needs to be a bit more generic there as the same method is used for listing unmanaged isntances
There was a problem hiding this comment.
@shwstppr Sure, we use also only IDE, SCSI controller but for me it sounds critical in case of other/new controller to ingest vm's without volumes . I think from user perspektive it is inconsistent to see that the vm is ingested but is unusable.
|
Trillian test result (tid-3354)
|
 shwstppr
left a comment
shwstppr
left a comment
There was a problem hiding this comment.
LGTM on changes. If we can add an exception as discussed here, https://github.com/apache/cloudstack/pull/4548/files#r545656572, that will be great
|
@blueorangutan package |
|
@rhtyd a Jenkins job has been kicked to build packages. I'll keep you posted as I make progress. |
|
Packaging result: ✔centos7 ✔centos8 ✔debian. JID-2504 |
|
@blueorangutan test |
|
@rhtyd a Trillian-Jenkins test job (centos7 mgmt + kvm-centos7) has been kicked to run smoke tests |
shwstppr
left a comment
There was a problem hiding this comment.
Looks good to me except the error message which can be more generic
...ns/hypervisors/vmware/src/main/java/com/cloud/hypervisor/vmware/resource/VmwareResource.java
Outdated
Show resolved
Hide resolved
| String num = disk.getLabel().replaceAll("\\D", ""); | ||
| // return 0 if no digits found | ||
| return num.isEmpty() ? 0 : Integer.parseInt(num); | ||
| return disk.getPosition() + (disk.getControllerUnit() * 100); |
There was a problem hiding this comment.
I think IDE and generic SCSI (VirtualSCSIController) will cover all disk controllers. If we are getting any other type of VirtualController as a disk, an exception seems correct to me. However, the error message needs to be a bit more generic there as the same method is used for listing unmanaged isntances
…vmware/resource/VmwareResource.java Co-authored-by: Abhishek Kumar <[email protected]>
| instanceDisk.setController(DiskControllerType.none.toString()); | ||
| String msg = String.format("Controller of disk %s is unsupported", instanceDisk.getLabel()); | ||
| s_logger.error(msg); | ||
| throw new Exception(msg); |
There was a problem hiding this comment.
@DK101010 I think on failure you can decide to fail the entire VM ingestion by (a) returning an empty list and let the user of the getUnmanageInstanceDisks method handle the case (when disk list is empty throw an exception), or (b) in the generic exception handler, instead of Exception throw an UnsupportedOperationException add another handler for the specific exception. cc @shwstppr
There was a problem hiding this comment.
@rhtyd @DK101010 same method is used when listUnmanagedINstances API is called so I'm not sure if we would want the complete API to raise an exception when disks for one particular VM is not found. In my opinion, we can log the error here and return the list of disks for the VM as empty. With an empty list of disks VM import with automatically fail with existing check
https://github.com/apache/cloudstack/blob/master/server/src/main/java/org/apache/cloudstack/vm/UnmanagedVMsManagerImpl.java#L942-L944
If we want to go with the above approach of returning empty disks list, we can clear the instanceDisks list variable in the catch block
There was a problem hiding this comment.
@shwstppr @rhtyd ok, then I will modify the exception msg and clear the list in the catch block. Thanks you two for help.
There was a problem hiding this comment.
@shwstppr ahh sorry, I had not checked that you have already changed the msg :D.
|
@blueorangutan package |
|
@shwstppr a Jenkins job has been kicked to build packages. I'll keep you posted as I make progress. |
|
Packaging result: ✔centos7 ✔centos8 ✔debian. JID-2512 |
GabrielBrascher
left a comment
There was a problem hiding this comment.
Code LGTM. I did not test it, though.
|
Packaging result: ✔centos7 ✔centos8 ✔debian. JID-2541 |
shwstppr
left a comment
There was a problem hiding this comment.
Needs changes, testing. Order of ROOT disk is coming incorrect
| String num = disk.getLabel().replaceAll("\\D", ""); | ||
| // return 0 if no digits found | ||
| return num.isEmpty() ? 0 : Integer.parseInt(num); | ||
| return disk.getPosition() + (disk.getControllerUnit() * 100); |
There was a problem hiding this comment.
@DK101010 I'm not sure if this formula is giving correct position/order for the disk.
I tried listUnamanagedInstance API for a VM with 2 data disks and results were incorrect with this change
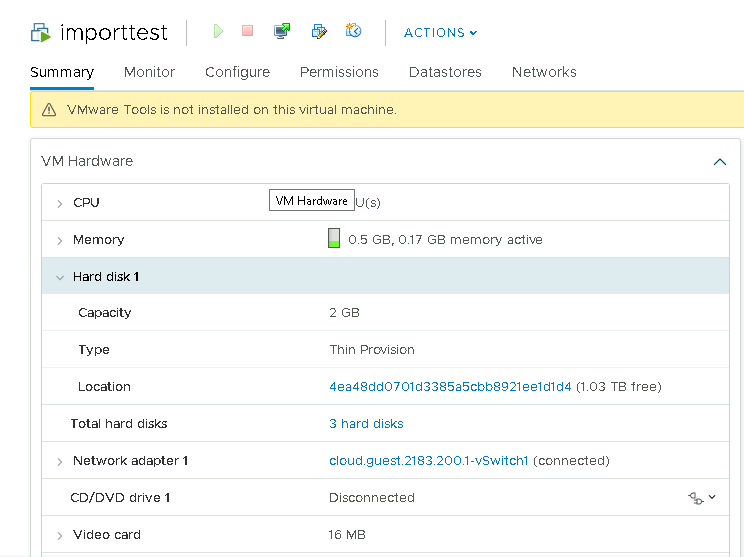
With changes - Root disk is showing up at second position in order
> list unmanagedinstances clusterid=2b35fefc-892a-4393-9ccf-30229c1a999b name=importtest
{
"count": 1,
"unmanagedinstance": [
{
"clusterid": "2b35fefc-892a-4393-9ccf-30229c1a999b",
"cpucorepersocket": 1,
"cpunumber": 1,
"cpuspeed": 0,
"disk": [
{
"capacity": 21474836480,
"controller": "lsilogic",
"controllerunit": 0,
"datastorehost": "10.10.0.16",
"datastorename": "4ea48dd0701d3385a5cbb8921ee1d1d4",
"datastorepath": "/acs/primary/pr4385-t3314-vmware-65u2/pr4385-t3314-vmware-65u2-esxi-pri2",
"datastoretype": "NFS",
"id": "35-2000",
"imagepath": "[4ea48dd0701d3385a5cbb8921ee1d1d4] importtest/importtest_61.vmdk",
"label": "Hard disk 2",
"position": 0
},
{
"capacity": 2147483648,
"controller": "ide",
"controllerunit": 0,
"datastorehost": "10.10.0.16",
"datastorename": "4ea48dd0701d3385a5cbb8921ee1d1d4",
"datastorepath": "/acs/primary/pr4385-t3314-vmware-65u2/pr4385-t3314-vmware-65u2-esxi-pri2",
"datastoretype": "NFS",
"id": "35-3001",
"imagepath": "[4ea48dd0701d3385a5cbb8921ee1d1d4] importtest/importtest_62.vmdk",
"label": "Hard disk 1",
"position": 1
},
{
"capacity": 5368709120,
"controller": "lsilogic",
"controllerunit": 0,
"datastorehost": "10.10.0.16",
"datastorename": "4ea48dd0701d3385a5cbb8921ee1d1d4",
"datastorepath": "/acs/primary/pr4385-t3314-vmware-65u2/pr4385-t3314-vmware-65u2-esxi-pri2",
"datastoretype": "NFS",
"id": "35-2001",
"imagepath": "[4ea48dd0701d3385a5cbb8921ee1d1d4] importtest/importtest_63.vmdk",
"label": "Hard disk 3",
"position": 1
}
],
"hostid": "fd9a2641-ce6e-456e-be78-4b1b63c2b2ac",
"memory": 512,
"name": "importtest",
"nic": [
{
"adaptertype": "E1000",
"id": "Network adapter 1",
"macaddress": "02:00:44:4f:00:12",
"networkname": "cloud.guest.2183.200.1-vSwitch1",
"vlanid": 2183
}
],
"osdisplayname": "CentOS 4/5 or later (64-bit)",
"osid": "centos64Guest",
"powerstate": "PowerOn"
}
]
}
Without change - Root disk at first place
> list unmanagedinstances clusterid=2b35fefc-892a-4393-9ccf-30229c1a999b name=importtest
{
"count": 1,
"unmanagedinstance": [
{
"clusterid": "2b35fefc-892a-4393-9ccf-30229c1a999b",
"cpucorepersocket": 1,
"cpunumber": 1,
"cpuspeed": 0,
"disk": [
{
"capacity": 2147483648,
"controller": "ide",
"controllerunit": 0,
"datastorehost": "10.10.0.16",
"datastorename": "4ea48dd0701d3385a5cbb8921ee1d1d4",
"datastorepath": "/acs/primary/pr4385-t3314-vmware-65u2/pr4385-t3314-vmware-65u2-esxi-pri2",
"datastoretype": "NFS",
"id": "35-3001",
"imagepath": "[4ea48dd0701d3385a5cbb8921ee1d1d4] importtest/importtest_62.vmdk",
"label": "Hard disk 1",
"position": 1
},
{
"capacity": 21474836480,
"controller": "lsilogic",
"controllerunit": 0,
"datastorehost": "10.10.0.16",
"datastorename": "4ea48dd0701d3385a5cbb8921ee1d1d4",
"datastorepath": "/acs/primary/pr4385-t3314-vmware-65u2/pr4385-t3314-vmware-65u2-esxi-pri2",
"datastoretype": "NFS",
"id": "35-2000",
"imagepath": "[4ea48dd0701d3385a5cbb8921ee1d1d4] importtest/importtest_61.vmdk",
"label": "Hard disk 2",
"position": 0
},
{
"capacity": 5368709120,
"controller": "lsilogic",
"controllerunit": 0,
"datastorehost": "10.10.0.16",
"datastorename": "4ea48dd0701d3385a5cbb8921ee1d1d4",
"datastorepath": "/acs/primary/pr4385-t3314-vmware-65u2/pr4385-t3314-vmware-65u2-esxi-pri2",
"datastoretype": "NFS",
"id": "35-2001",
"imagepath": "[4ea48dd0701d3385a5cbb8921ee1d1d4] importtest/importtest_63.vmdk",
"label": "Hard disk 3",
"position": 1
}
],
"hostid": "fd9a2641-ce6e-456e-be78-4b1b63c2b2ac",
"memory": 512,
"name": "importtest",
"nic": [
{
"adaptertype": "E1000",
"id": "Network adapter 1",
"macaddress": "02:00:44:4f:00:12",
"networkname": "cloud.guest.2183.200.1-vSwitch1",
"vlanid": 2183
}
],
"osdisplayname": "CentOS 4/5 or later (64-bit)",
"osid": "centos64Guest",
"powerstate": "PowerOn"
}
]
}
There was a problem hiding this comment.
Hi @shwstppr, the list is correct sorted by controller id and position. Works like I want. Your root disk is on controller Id 0 and position 1 and you have two disk on the same position. I'm a little bit confused. In my mind vmware puts the root disk in every case on controller id 0 and position 0.
There was a problem hiding this comment.
Hi @DK101010, I'm not sure why two disks have same position. To get this unmanaged VM. I just created a VM in cloudstack, added two data disks to it and then cloned the vm in vcenter.
There was a problem hiding this comment.
@shwstppr ahh ok you have two controller(ide, lsilogic), But in my opinion it makes no sense that you have one disk on one controller on position one. Also should increment the controller id, when you use more the one controller. And for this reason works this feature not correct. I think you found a other bug.
There was a problem hiding this comment.
Hi @shwstppr, I talked with my team about this behavior. First, your controller ids are correct. Increments are per controller type. For this reason is my implementation not better as the old one. Perhaps we could check in the sort algorithm if device type == scsi controller, but then it isn't no longer possible to boot from other controller types. It exist no safety way to find out which disk is bootable. The only way to get sure that CS use the right volume is that the user indicates during the ingest process via rest call which volume is the right. Therefore I think we should close this pull request. What do you think?
There was a problem hiding this comment.
@DK101010 then is it better to add a new param in importUnamangedInstance API, something like rootdiskid? cc @rhtyd @PaulAngus
There was a problem hiding this comment.
@shwstppr yes, for example, but in my mind it should be optional for the user and when not set then works like now via sorting of disk names.
Description
This PR...
Types of changes
Feature/Enhancement Scale or Bug Severity
Feature/Enhancement Scale
Bug Severity
Screenshots (if appropriate):
How Has This Been Tested?
Adapt mockito test to check the new behavior